




关于 MYSQL 基本语法总结
MySQL 基本语法
概述
在数据库管理中,SQL 语句可以分为几个不同的类别,主要包括 DDL (数据定义语言) 和 DML (数据操纵语言),还有 DCL (数据控制语言) 和 TCL (事务控制语言)。每个类别都有其特定的用途和对应的命令集。
DDL (数据定义语言)
DDL,即数据定义语言,主要用于定义和修改数据库结构。这些命令对数据库的结构进行操作,如创建表、修改表结构、删除表等。
常见的 DDL 命令包括:
CREATE:用于创建新的数据库或数据库表ALTER:用于修改现有数据库对象的结构,如添加、删除或修改表中的列DROP:用于删除整个数据库或表TRUNCATE:用于删除表中的所有行,但不删除表本身
DQL(数据查询语言)
数据库查询语言。关键字:SELECT … FROM … WHERE。
DML (数据操纵语言)
DML,即数据操纵语言,主要用于添加、删除、更新和查询数据库记录。
常见的 DML 命令包括:
INSERT:向表中插入新的数据行UPDATE:更新表中的现有数据DELETE:从表中删除数据
DCL (数据控制语言)
DCL,即数据控制语言,用于定义数据库的安全策略和权限控制。
常见的 DCL 命令包括:
GRANT:授权用户访问和操作数据库的权限REVOKE:撤销已经授予的权限
TCL (事务控制语言)
TCL,即事务控制语言,用于管理事务,确保数据的完整性。
常见的 TCL 命令包括:
COMMIT:提交当前事务,使自上一个COMMIT或ROLLBACK以来进行的所有修改成为永久性的ROLLBACK:回滚当前事务,撤销自上一个COMMIT或ROLLBACK以来进行的所有修改SAVEPOINT:在事务中设置一个保存点,可以回滚到该点而不是完全回滚事务
这些命令集使数据库管理员和开发者能够有效地管理和操作数据库系统。使用时需要根据实际需要选择合适的命令类型。
DDL 语句-创建表
1 | CREATE TABLE example_table ( |
添加列
1 | ALTER TABLE example_table |
删除列
1 | ALTER TABLE example_table |
修改列类型
1 | ALTER TABLE example_table |
DQL/DML 语句
查询操作
查询所有管理员信息
1 | -- 查询所有管理员的详细信息 |
查询特定管理员
1 | -- 根据用户名查询管理员信息 |
查询特定列
1 | -- 查找数据库某几列 |
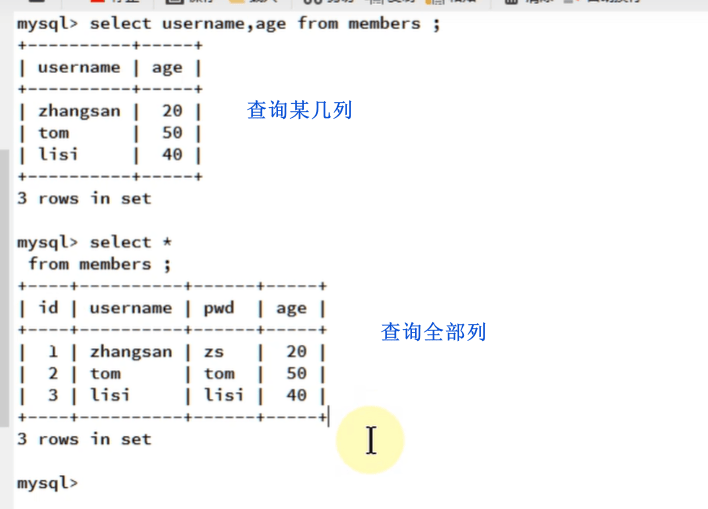
多个查询条件使用 and 链接

插入操作
添加新管理员
1 | -- 插入一个新的管理员记录INSERT INTO admins (username, password, name, avatar, phone, email) |
删除操作
删除指定管理员
1 | -- 删除用户名为 'zhangsan' 的管理员DELETE FROM admins WHERE username = 'zhangsan'; |
注意:开自动递增,id 删除后新建数据,id 不会继续递增而是跳过删除的数据
想要 id 重新开始排序:截断表(清空排序)
修改操作
更新管理员信息
1 | -- 更新管理员 'liulei07' 的电子邮箱和电话号码UPDATE admins |
分组与聚合统计
统计各个用户名下的记录数
1 | -- 统计每个用户名下的记录数量SELECT username, COUNT(*) AS user_count |
在 SQL 中,分组操作通常与GROUP BY 子句结合使用,这允许你按照一个或多个列对结果集进行分组。这通常用于与聚合函数(如 COUNT, SUM, AVG, MAX, MIN 等)结合,以对各个分组进行统计计算。
获取最大、最小管理员 ID
1 | -- 获取当前管理员中的最大和最小 IDSELECT MAX(admin_id) AS max_id, MIN(admin_id) AS min_id |
关联查询
创建收货地址表
创建一个新的表 shipping_addresses,该表包含管理员的收货地址详情:
1 | CREATE TABLE shipping_addresses ( |
插入关联数据
1 | -- 插入管理员 liulei07 的收货地址INSERT INTO shipping_addresses (admin_id, address, city, state, postal_code, country) |
进行关联查询操作
1 | -- 查询每个管理员及其所有收货地址SELECT a.username, a.name, sa.address, sa.city, sa.state, sa.postal_code, sa.country |
这个查询将返回管理员的用户名和姓名以及他们的每个收货地址的详细信息。
查询特定管理员的所有收货地址
如果您想要查询特定管理员的所有收货地址,可以修改查询条件,例如查询管理员 liulei07:
1 | -- 查询管理员 liulei07 的所有收货地址SELECT a.username, a.name, sa.address, sa.city, sa.state, sa.postal_code, sa.country |
JOIN
在 SQL 中,连接(JOIN)是用来合并两个或多个表的行的方法,根据表之间的共同字段来合并。连接类型决定了查询如何选择行进行合并。以下是常见的连接类型及其用途:
1. INNER JOIN(内连接)
用途:返回两个表中匹配条件的行。如果一行在一个表中匹配但在另一个表中不匹配,则不会显示这行。
示例:
1 | SELECT *FROM table1 |
2. LEFT JOIN(左连接)
用途:返回左表(table1)的所有行和右表(table2)中匹配的行。如果右表没有匹配的行,则结果中这部分将为 NULL。
示例:
1 | SELECT *FROM table1 |
3. RIGHT JOIN(右连接)
用途:返回右表(table2)的所有行和左表(table1)中匹配的行。如果左表没有匹配的行,则结果中这部分将为 NULL。
示例:
1 | SELECT *FROM table1 |
4. FULL OUTER JOIN(全外连接)
用途:返回两个表中的所有行。当某行在一个表中有匹配而在另一个表中无匹配时,对应的无匹配表的部分将为 NULL。注意,MySQL 不直接支持 FULL OUTER JOIN,但可以通过 UNION 实现。
示例(模拟全外连接):
1 | SELECT *FROM table1 |
5. CROSS JOIN(交叉连接)
用途:返回第一个表的每一行与第二个表的每一行的笛卡尔积。如果两个表分别有 5 行和 4 行,那么结果将有 20 行。
示例:
1 | SELECT *FROM table1 |
6. SELF JOIN(自连接)
用途:是一种特殊情况的内连接,表通过自身与自身连接,常用于组织结构、层级数据等场景。
示例:
1 | SELECT a.name AS EmployeeName, b.name AS ManagerName |
在 SQL 中进行 JOIN 操作时,ON 关键字是用来指定 JOIN 的条件的,它定义了两个表如何关联在一起。通过 ON 条件,SQL 引擎能够决定如何精确地匹配来自两个表的行。这个条件通常涉及到两个表中共有的一个或多个字段。